How to Use the New Screening Feature
A deep dive into the new percolation feature to surface hidden entities and why it can be called "reverse search".
OpenAleph has built a reputation as a powerful search tool. As a result, much of the search experience has focused on retrieving documents based on keywords. This approach answers the question: "What data do I have about this entity?" The results can include everything from PDFs and emails to structured FollowTheMoney data.
Searching data in an OpenAleph instance typically starts with an interesting name: a person, company, place, vessel, or other entity. It can help a journalist determine whether someone appears in a leak. What it cannot do, however, is help them discover who else appears in that leak.
To address this, we have been expanding OpenAleph to support a more exploratory approach to search. The first step was the Discovery feature, which allows a journalist to start with a name and immediately see other names that are closely associated with it across all of the documents in an instance. Discovery surfaces links between people, companies, places, and other entities based on how frequently they appear together in those documents.
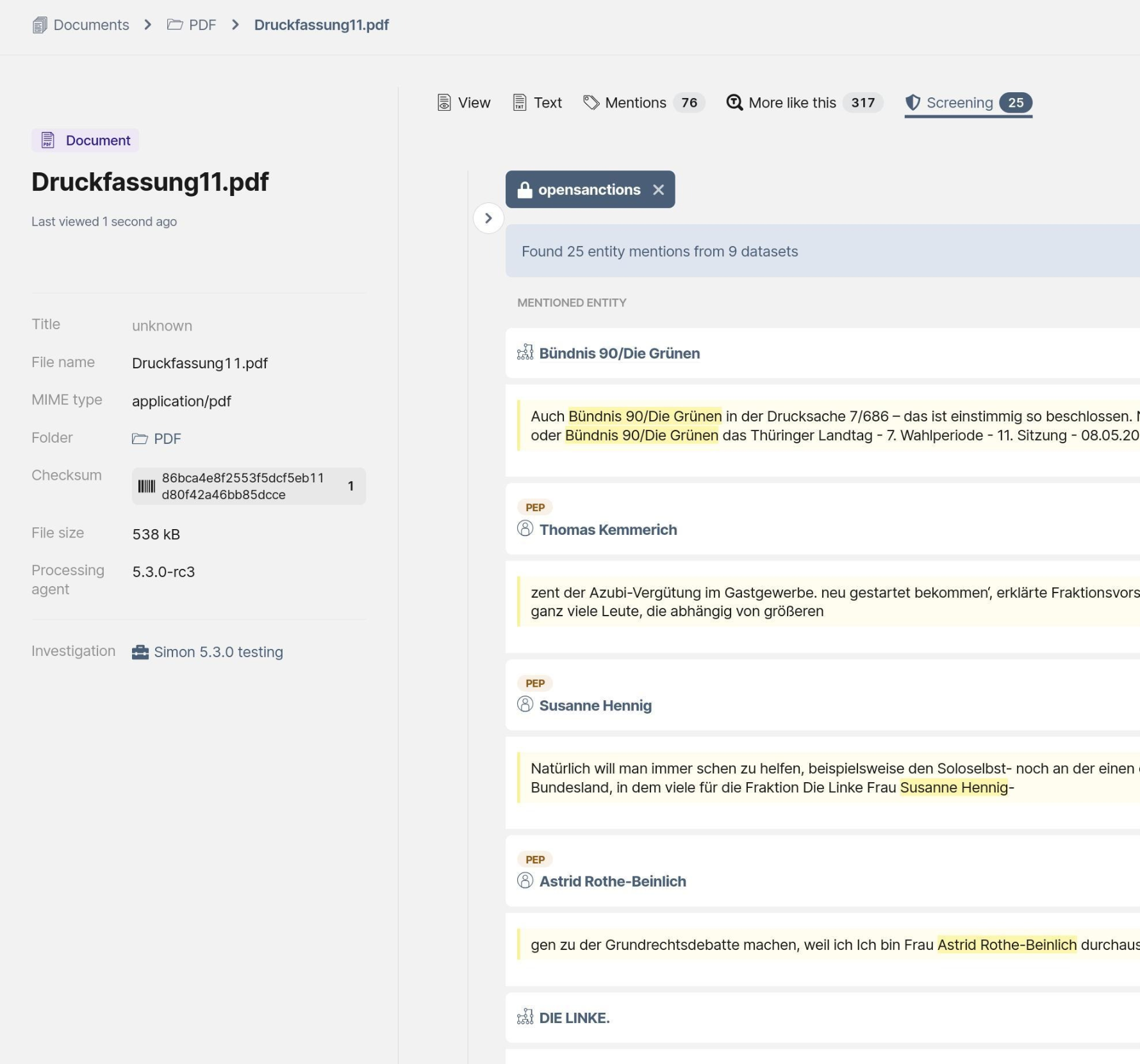
Now we're taking another step in that direction with the addition of a Screening tab for all document types in OpenAleph, including PDFs, Microsoft Office files, emails, and more. In this tab, a percolation query identifies all FollowTheMoney entities stored in an OpenAleph instance that are also mentioned in a given document. Think of it as cross-referencing for unstructured data.
Both Discovery and Screening rely on deterministic Elasticsearch algorithms. Given the same data, they will always produce the same results. There is also a clear paper trail explaining why two entities are associated based on their representation in the search index. This allows us to control how loosely or tightly correlated data must be before it is surfaced.
Percolation is search, but in reverse
A traditional search works by sending a keyword or name to the Elasticsearch index and returning all documents that match it. Percolation works like search in reverse: Send a document to the index, and retrieve a list of entities that appear in this document as search results. Alongside each entity, the Elasticsearch index stores a query composed of the entity properties that can contain a name, such as name, alias, previousName. Any entity that has one of it's names mentioned in the given document will be returned as a result in the Screening feature.
Using the percolation feature is effectively taking a document and asking: "Which of these stored queries would match this document?"
Another way to think about the Screening tab is this: if a user searched for the name of any entity that appears in the Screening tab, OpenAleph would return that document.
As journalists use OpenAleph, they build a library of structured FollowTheMoney entities, often including reference datasets such as sanctions lists, company registries, or PEP data. At the same time, they collect unstructured information—documents, court records, emails, research notes, and other natural-language sources. Percolation bridges these two worlds by allowing journalists to use an unstructured document to search their entire library of structured FollowTheMoney data in reverse, surfacing any entities mentioned in the document and revealing where else they appear across an OpenAleph instance.
This means a journalist can rediscover entities they created while mapping public tenders, land registries, or other datasets, even if those entities originated in entirely different investigations. By connecting new documents to existing structured knowledge, Screening helps surface relationships and leads that might otherwise remain hidden.
Enabling percolation and fine-tuning it
The Screening tab for a document is populated with structured entities already stored in OpenAleph, such as Persons, Companies, and Vessels, whose names also appear in the document. The matching is not exact; instead, it tolerates some variation in spelling. The technical documentation explains the matching behavior in more detail. For maintainers of self-hosted OpenAleph instances, these settings can also be adjusted to make name matching either stricter or more permissive.
Administrators of self-hosted OpenAleph instances can enable percolation by setting the environment variable OPENALEPH_SEARCH_PERCOLATION=1 or by setting percolation: true in the .env file. They should then run openaleph-search upgrade in the API container to ensure the relevant index includes the query percolator field. Finally, each investigation or dataset containing relevant entities must be re-indexed so that percolation queries are generated for existing FollowTheMoney entities. Any entities added after percolation is enabled will automatically have corresponding queries stored.
The synonym functionality used by OpenAleph search, which allows journalists to search across different spellings and writing systems, is not applied during percolation directly. This means that a document containing the name "Vladimir Putin" will not match a Person entity whose name property is only "Владимир Путин". However, one of the core features of FollowTheMoney is that a single entity can store multiple names and name variants for the same person. If the Putin entity includes both "Vladimir Putin" and "Владимир Путин" as names, then a document containing either variant will match and surface that entity in the Screening results.
The future of search
OpenAleph has traditionally relied on two major features to surface interesting data: full-text search across entities and documents, and cross-referencing structured data (xref). Cross-referencing is useful for identifying entities that most likely describe the same real-world object but are scattered across different datasets, allowing them to be merged.
With features like the Discovery and Screening tabs, OpenAleph introduces contextual and relational search methods. These allow journalists to reuse datasets, leaks, and knowledge libraries built across previous investigations to contextualize new names and uncover connections that would otherwise remain hidden.